What is a Sampler in Stable Diffusion?
Introduction to Stable Diffusion Samplers
If you’re a casual user who just wants to create images easily and change the art styles, you can safely skip the samplers lesson. But if you’re a Stable Diffusion enthusiast that’s trying to squeeze higher quality and more control over your images, you’re definitely in the right place. Samplers are a part of the diffusion software that peel the curtain how the magic works. Let’s start with this clever diagram from Andrew Wong’s blog:

“To produce an image, Stable Diffusion first generates a completely random image in the latent space. The noise predictor then estimates the noise of the image. The predicted noise is subtracted from the image. This process is repeated a dozen times. In the end, you get a clean image.
This denoising process is called sampling because Stable Diffusion generates a new sample image in each step. The method used in sampling is called the sampler or sampling method.”
What’s the best sampler for Stable Diffusion?
It’s a touchy subject among weebs, perhaps it’s best if you experiment yourself. There are many comparison images and videos at the bottom of this page.
To see a list of samplers in PirateDiffusion, type this command:
/sampler
Here are some very opinioned reviews to arm you with a general sense of what each does:



** VIDEO: HOW TO USE THE SPECIAL LCM SAMPLER
Deeper into the tech
To better understand samplers, you must first understand how the diffusion process works. Think about a blurry image, and how your eye gradually brings it into focus. Computers do the same with diffusion: the general information is stored as noise, literally colorful dots that don’t make sense to the human eye. Consider this image: A sampler can process that noise and “focus” it into a photo. The sampler comes into play at the denoising step (bottom left)
A sampler can process that noise and “focus” it into a photo. The sampler comes into play at the denoising step (bottom left)
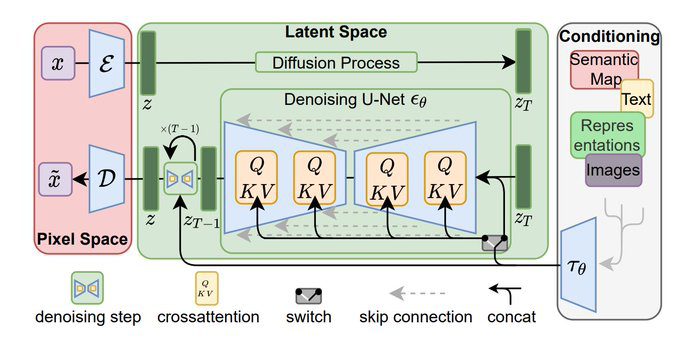 In other words, Diffusion models learn how to remove noise from images, paired with a description of the image, as a way of learning what images look like, and then to generate new ones.
But how do you go from pure noise to an image *exactly*? There are many answers to this question, and thus, resulting in thousands of different samplers available online. Thousands!
In other words, Diffusion models learn how to remove noise from images, paired with a description of the image, as a way of learning what images look like, and then to generate new ones.
But how do you go from pure noise to an image *exactly*? There are many answers to this question, and thus, resulting in thousands of different samplers available online. Thousands!
Comparisons
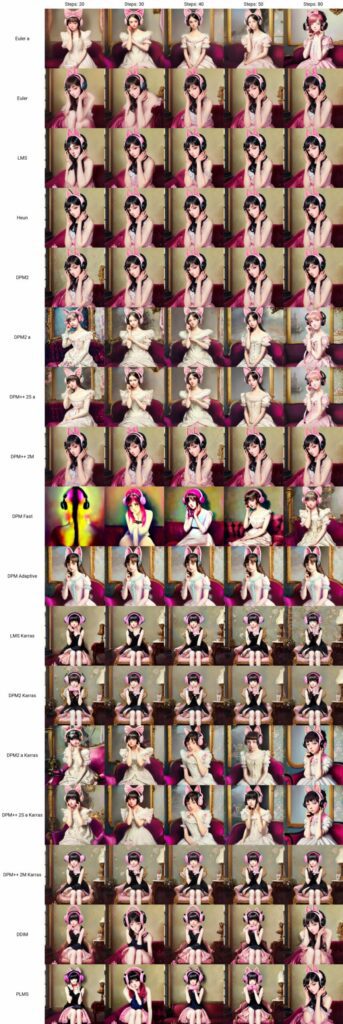
Can’t we just create a chart that compares each one? Remember – it varies greatly by prompt, so any chart we create would be inconclusive: What looks good in one prompt may look worse in a different prompt. The verdict is not out on that topic, and there is much debate about it online. Here are more comparisons with some unsupported or older ones. The big takeaway here is that you can save time and money by reducing the step count by working with a more “creative” sampler and get similar results.Pictured below: /steps:20 /steps:30 /steps:40


 For this specific prompt — Some samplers can do gentler details than others, like hair, eyes, and so forth… but that same sampler may not be as good for a building. If you have the free time, it’s a super interesting toy to play with. If you are in a hurry, just pick the one you like and add more steps and you can get similar results.
There are tons of comparisons at higher resolutions on google if you want to become a samplers savant. People make really detailed charts!
For this specific prompt — Some samplers can do gentler details than others, like hair, eyes, and so forth… but that same sampler may not be as good for a building. If you have the free time, it’s a super interesting toy to play with. If you are in a hurry, just pick the one you like and add more steps and you can get similar results.
There are tons of comparisons at higher resolutions on google if you want to become a samplers savant. People make really detailed charts!
 Go further: You can combine these with other techniques for a more striking image, such as SDXL /vass or one of our Upscalers
Go further: You can combine these with other techniques for a more striking image, such as SDXL /vass or one of our Upscalers